Bridge pattern with real-world example
In this tutorial, we will show the real-world problem and solve it with a bridge pattern.
Real-world business problem that I had in my real job
Our client is uploading his files into the AWS and the task of our application was to check for new files every hour. If it finds any new file, we need to process that file in our application. The only tricky part is that he wants to upload to different platforms: AWS, GCP, Azure, and even on some remote servers that are not on the cloud. Also, files are not always in the same format. Sometimes, the client uploads an Excel file, CSV, some custom format, etc. The last thing is the content of the file is different. He can upload a list of books, a list of publishers, etc.
So, a few possible use cases might look like this:
- books in CSV format uploaded into the AWS
- Authors are uploaded into the GCP in Excel format, etc.
Expectations were to cover all possible combinations.
How do we recognize this is the bridge pattern?
Parts are moving around three axes:
- Type of storage(AWS, GCP, etc.)
- Format(CSV, Excel, etc.)
- Content(Book, Publisher)
Every one of those axes is one hierarchy. Reader hierarchy is tasked with reading files for you using InputStream read(String location). You give the location of the file to the reader and the output is InputStream. Take note that the result is not Book or Publisher. The Reader is not capable of parsing things from the file. It just reads for you and returns you an InputStream as a result. The next step is to pass that InputStream to the Parser. The Parser can parse content from the InputStream and return you a Book.
The only last problem is that even Parser has too two responsibilities:
- Parse specific format
- Parse specific content.
That is coupling two of our axes and it’s not a good idea. When you see that you have moving parts that vary along two or more axes and every axe is one hierarchy and axes need to work together, a bridge pattern is the solution.
UML diagram
Let’s take a look at the UML diagram before coding:
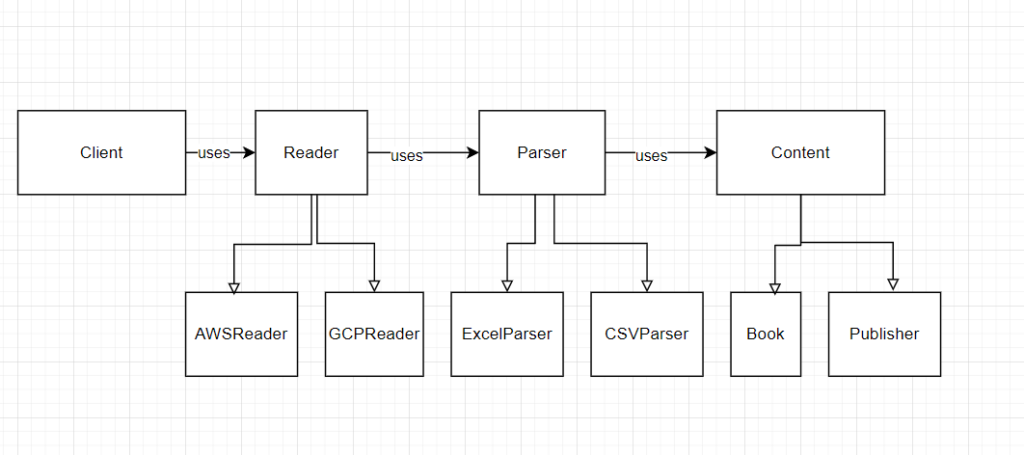
Simple diagram. We have three hierarchies: Reader, Parser, and Content. The Reader does its job(reading from location and returning InputStream and delegated parsing to the Parser. Parser does the format parsing but delegates content-specific things to the Content)
Coding time
Let’s start with the reader:
public interface Reader {
InputStream read(String location);
}
public class AWSReader implements Reader {
@Override
public InputStream read(String location) {
//Handling auth and reading from aws s3 using aws libraries
}
}
public class GCPReader implements Reader {
@Override
public InputStream read(String location) {
//Handling auth and reading from Google Cloud Storage using GCP libraries
}
}
I didn’t show the real implementation code using AWS or GCP libraries since that’s off-topic. What is important to realize is that handling everything related to the AWS(reading from AWS but also doing authorization or authentication if needed) is inside the AWSReader. You won’t repeat that AWS code anywhere else. The same applies to GCP. The next part of our bridge pattern is the Parser:
public interface Parser {
List<Content> parse(InputStream inputStream, String fileName);
}
public class ExcelParser implements Parser {
private final ContentFactory factory;
public ExcelParser(ContentFactory factory) {
this.factory = factory;
}
@Override
public List<Content> parse(InputStream inputStream, String fileName) {
List<Content> parsedObjects = new ArrayList<>();
try {
Workbook wb = WorkbookFactory.create(inputStream);
Sheet sheet = wb.getSheetAt(0);
Row row;
Cell cell;
int rows; // No of rows
rows = sheet.getPhysicalNumberOfRows();
int cols = 0; // No of columns
int tmp = 0;
// This trick ensures that we get the data properly even if it doesn't start from the first few rows
for(int i = 0; i < 10 || i < rows; i++) {
row = sheet.getRow(i);
if(row != null) {
tmp = sheet.getRow(i).getPhysicalNumberOfCells();
if(tmp > cols) cols = tmp;
}
}
for(int r = 0; r < rows; r++) {
Content obj = factory.create(fileName);
row = sheet.getRow(r);
if(row != null) {
for(int c = 0; c < cols; c++) {
cell = row.getCell((short)c);
if(cell != null) {
cell.setCellType(CellType.STRING);
obj.setField(
obj.getExcelMetadata().get(c).getSetterFunction(),
obj.getExcelMetadata().get(c).getReadingFunction().apply(cell.getStringCellValue())
);
}
}
parsedObjects.add(obj);
}
}
} catch(Exception ioe) {
ioe.printStackTrace();//we should handle exception properly here
}
return parsedObjects;
}
}
This one is a bit more complicated and requires explanation. You may need to go through this code a few times to understand it but when you do understand it, it will fit perfectly. First of all, take a look at the signature of the parse method in the Parser interface. fileName is an input parameter because content is determined based on the name of the file. For example, if the name of the file contains *book* then the content of the file is a list of books.
Parser does too much!
The next thing to realize is that this Parser handles both format and content. We said earlier that those two things are different responsibilities and that those should be decoupled and we will stick to it. This Parser that we are looking at handles only a format thing and it delegates content job! Let’s take a quick look at the ExcelParser implementation. Notice that this dependency ContentFactory creates a new object based on the file name:
public class ContentFactory {
public Content create(String fileName) {
if (fileName.contains("book")) {
return new Book();
}
if (fileName.contains("publisher")) {
return new Publisher();
}
throw new RuntimeException("Not supported entity: " + fileName);
}
}
Ok, let’s get back to the ExcelParser. You can parse Excel file using a library called Apache POI.
But also you should know that the book file contains the following columns: “authorName”, “name”, and “price”. Also, it should be noted that the price is the Integer data type. That means that if you read “price” from the Excel file and you get a String you need to convert that String to an Integer.
The first part of the job(with Apache POI library) is done inside the Parser but the second part where we do some content-specific staff is delegated! Let’s take a look at this part of the implementation:
for(int r = 0; r < rows; r++) {
Content obj = factory.create(fileName);
row = sheet.getRow(r);
if(row != null) {
for(int c = 0; c < cols; c++) {
cell = row.getCell((short)c);
if(cell != null) {
cell.setCellType(CellType.STRING);
obj.getExcelMetadata().get(c).getSetterFunction().accept(
obj.getExcelMetadata().get(c).getReadingFunction().apply(cell.getStringCellValue())
);
}
}
parsedObjects.add(obj);
}
}
Everything else besides this for loop is just some Apache POI job (like opening the sheet and similar things) specific for Excel. But here you can see that for every row in the Excel, we create a new object: Content obj = factory.create(fileName); using our factory. Then, inside the if(cell != null) we are parsing cell data.
If you look closely inside the loop you cannot conclude which content we are parsing! Do we parse books or publishers? Also, you cannot conclude which columns are included in the book file and which are in the publisher file. That knowledge is delegated to the Content hierarchy!
Inside the Parser implementation, we would like to do two things:
- Read from the cell somehow.
- On the
objobject, we need to call the appropriate setter to set the value we just read from the cell.
But how do we know if this cell is String or Integer and should we do that conversion before calling setter? How do we know if we are currently reading the authorName or the price field? Well, every Content object has a method getExcelMetadata that gives you metadata about the obj. It gives you readingFunction which should be applied while reading from the excel and setterFunction which should be applied when setting data to the object obj. Now you can better understand this part of the code:
obj.getExcelMetadata().get(c).getSetterFunction().accept(
obj.getExcelMetadata().get(c).getReadingFunction().apply(cell.getStringCellValue())
);
You retrieve excelMetadata and then apply readingFunction to the cell value(cell.getStringCellValue()). When you have the result you apply the appropriate setter by using setterFunction.
Our Content hierarchy looks like this:
public interface Content {
<T> Map<Integer, ExcelFieldMetadata<T>> getExcelMetadata();
}
public class Book implements Content {
private String authorName;
private String name;
private double price;
public String getAuthorName() {
return authorName;
}
public void setAuthorName(String authorName) {
this.authorName = authorName;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public double getPrice() {
return price;
}
public void setPrice(Double price) {
this.price = price;
}
@Override
public Map<Integer, ExcelFieldMetadata> getExcelMetadata() {
Map<Integer, ExcelFieldMetadata> map = new HashMap<>();
ExcelFieldMetadata<Double> priceFieldMetadata =
new ExcelFieldMetadata<>(Double::parseDouble, this::setPrice);
ExcelFieldMetadata<String> authorNameFieldMetadata =
new ExcelFieldMetadata<>(Function.identity(), this::setAuthorName);
ExcelFieldMetadata<String> nameFieldMetadata =
new ExcelFieldMetadata<>(Function.identity(), this::setName);
map.put(0, authorNameFieldMetadata);
map.put(1, nameFieldMetadata);
map.put(2, priceFieldMetadata);
return map;
}
}
@Value
public class ExcelFieldMetadata <T> {
Function<String, T> readingFunction;
Consumer<T> setterFunction;
}
Implementation of the getExcelMetadata is interesting. On this line new ExcelFieldMetadata<>(Double::parseDouble, this::setPrice); we define that when parsing this particular field we need to apply parseDouble method(which means that you need to convert the String that we get from Excel to the double(because the price is of type double)). Also, we define that we want to call setPrice method to set that field. At the end, we have map.put(2, priceFieldMetadata);. From this line, it can be concluded that this field is third from the beginning. We can also see metadata for other fields as well.
And that’s it, our pattern is almost done! Let’s see a few minor tweaks for the end and how to extend this code.
How to extend this code
If we want to add a new Reader(let’s say Azure) we just need to create a new class AzureReader implements Reader and nothing else. We don’t need to bother with Excel, csvs, books, publishers, etc. The same thing is true if we want to add new content Car. We extend Content and that’s it we don’t bother with AWS, Excel, etc. Adding a new format requires adding a new metadata method into the Content class but that makes sense since now we have new specific knowledge for the content. Let’s say we add CsvParser we need to know particularly for the book in which order fields are, which field is which type, etc.
Last small thing
You can see that the Parser is connected to the Content and those two interact with each other but the Reader is connected neither to the Parser nor to the Content. Another question is: “Does it make sense to do something like this?”:
InputStream inputStream = new AWSReader().read(location);
Well, probably not since you got the InputStream and you still have to convert that InputStream to the book. That means that the Reader always goes with the Parser. A more logical thing is to rewrite Reader to this:
public abstract class Reader {
private final Parser parser;
public Reader(Parser parser) {
this.parser = parser;
}
public List<Content> read(String location) {
return parser.parse(doRead(location), location);
}
protected abstract InputStream doRead(String location);
}
public class AWSReader extends Reader {
public AWSReader(Parser parser) {
super(parser);
}
@Override
protected InputStream doRead(String location) {
//Handling auth and reading from aws s3 using aws libraries
}
}
As you can see now Parser is the dependency of the Reader. A minor change but this is how we connect two hierarchies(and we connect them because they always work together). If you want to use this reader you do that like this:
List<Content> result = new AWSReader(new ExcelParser(new ContentFactory())).read("books.xlsx");
Of course, you need to initialize proper Reader and Parser in your code(and not just hardcode Excel and AWS as I did) but that is not the scope of this tutorial.
Conclusion
And that’s it. You learned bridge pattern in the real world, instructive example!
Further reading
If you want to learn more about design patterns and best practices, here are the great resources:
- Patterns of Enterprise Application Architecture by Martin Fowler
- Domain-Driven Design: Tackling Complexity in the Heart of Software by Eric Evans. “Blue” book, that is along with the “red” book(Vernon’s book) the best material regarding the DDD topic. Note that those two books are very hard to understand(don’t be frustrated and quit because you cannot understand things easily)
- Implementing Domain-Driven Design by Vaughn Vernon
- Microservices Patterns by Chris Richardson. Great book to learn about Microservices patterns theory and how to implement them using Java
- Hexagonal architecture using Spring and Java. This is the article. Take a look at it and if you like it there is a short book linked at the bottom of the article. I went through the book and it is awesome!
- Patterns and Best Practices category on my website